The First 90 Days as a Startup CTO: What Actually Matters
When I started as a CTO, I had a plan. The plan was not to change anything yet.
A founder hires a CTO to act: to fix what is broken, to make the calls the last person would not, to prove in the first month that the hire was right. So “change nothing yet” sounds like dodging the job, and the first time I said it out loud to a founder, that is how it landed. It was the opposite of dodging. The fastest way to fail in your first 90 days as a startup CTO is to act before you understand the team, the system, and the business you have just walked into. The plan was to learn what worked and what did not, and only then to fix what was broken and protect what was working. The hard part, harder than any technical decision, was holding that line while everyone waited for me to do something.
What I did not fully appreciate then is how much of that learning lives outside the thing I was most tempted to look at first. When you join a team that already exists, the codebase is right there, waiting to be read, and it feels like the obvious place to start. It is not. Code is the most visible artifact in any engineering organization, and it is the easiest thing to mistake for the whole picture. The things that actually decided whether those first months worked were mostly not in the code at all.
This is the gap I want to write about: the distance between the plan you write in week one and the work that actually moves the company.
What does the code tell you, and what does it hide?
Here is the thing about a codebase: it tells you a lot, and most of it is true, but almost none of it is the part you need first.
A codebase tells you how the product works. It also tells you, if you read it carefully, the proficiency level of each person who wrote it. You can see who reaches for the clean abstraction and who copies the same block four times. That is real signal, and stepping into a team I had not hired myself, I paid attention to it.
What a codebase cannot tell you is why. Why a decision was made, what constraint forced it, what the team tried before that did not work, what they are quietly afraid will break if anyone touches it. That history rarely makes it into a comment.
The trap I watch people fall into is judging code on sight. Something looks ugly, or messy, or it does not follow a clean architectural pattern, and the new leader files it under “debt to fix.” But code that looks wrong at first glance is very often code that is wrong on purpose. The strange function with seven branches and a comment that says “do not remove” is usually not incompetence. It is a record of seven things that broke in production and got handled one at a time. You have to understand the decisions behind the code before you can judge it well, and you cannot do that by reading the code alone. You have to ask the person who wrote it.
This is the point Joel Spolsky made about Netscape twenty-five years ago, and it has not aged. In “Things You Should Never Do, Part I”, he argued that the instinct to rewrite a working codebase from scratch is almost always a mistake. As he put it, “old code doesn’t rust, it gets better, as bugs are fixed.” Every ugly edge case is accumulated knowledge. Netscape rewrote their browser, spent roughly three years shipping nothing new, and handed the market to Internet Explorer in the process. The lesson is not really about rewriting. It is about respecting the knowledge embedded in things that look bad, before you decide they are bad.
Will Larson, the former CTO of Calm and an engineering leader at Stripe, has a phrase for the failure mode here. He calls it “judging without context.” Most of the bad decisions you find in a system were good decisions in a context that no longer exists. Walk in with opinions before you understand that context, and you lose the room faster than any technical misstep could cost you.
The listening work that does not feel like work
If the code is not the place to start, the people are. And this is where I learned the lesson that changed how I lead.
I have come to believe that communication is the most important tool in my belt. Not architecture, not language choice, not the cleverness of a system design. Every decision I make depends on information I do not have until someone tells me, and people only tell you the real version once they trust you will not use it against them. The listening tour is not soft, then. It is intelligence gathering, and the things worth hearing are not in any dashboard: where work actually stalls, what the team has already tried and abandoned, and what they are quietly afraid you will change.
Here is what that looked like in practice. I decided the team needed to adopt AI coding agents, and the pushback was immediate. The stated objection was code quality: the tools produced sloppy work, they slowed good engineers down, pick the reason. I took it seriously, but I was fairly sure it was not the real objection. The real one, underneath, was fear. If a model could do an impressive share of the work, what happened to the people who used to do it? You do not reach that fear by arguing about code quality. You reach it by having enough honest conversations that people stop giving you the defensible answer and tell you the actual one.
So I did not mandate it and walk away. I ran a couple of workshops to show the team how to use the tools well, where they helped and where they produced exactly the garbage the engineers were worried about. I was direct about the thing under the surface: these tools raise the floor, but it is the expertise of a human engineer that turns their output into something you would actually ship, and that expertise was not getting less valuable. And I spent some of the trust I had built in those first weeks to give people honest reassurance about their jobs. The requirement stuck, not because I enforced it, but because the people under it no longer felt it was aimed at them. That is the return on the listening. You cannot buy it later, and you cannot fake it.
The decision I regret skipping: understanding how the business makes money
This is the part I most wish I had pushed on harder and earlier, and it is the part the standard advice covers least.
Early on, the company was a B2C product, and for a B2C product a single-tenant architecture was the right call. It was simpler, it shipped faster, and nothing about the business needed anything else. That decision was correct for the company we were at the time. The mistake came later, and it was mine.
The company decided to go after the B2B market, and B2B changed the ground under the architecture. Enterprise clients needed their data isolated from one another. Some needed it to live in a specific region to satisfy data residency rules. The single-tenant design that had been right for consumers was now the wrong shape for the business we were becoming. The honest response was to stop and rearchitect for multi-tenancy. What we did instead, under pressure to move fast, was layer multi-tenancy on top of an application that was never built for it. We worked around the original design, then worked around the workaround, then built a special case on top of that. Each patch was reasonable on its own. Together they were a slow accumulation of debt, and eventually we had to do the thing we had been avoiding: stop, redesign the data model, and rebuild a large part of the platform so it was multi-tenant by design instead of by patchwork. We paid for the rebuild, and we paid for all the patching we did first.
Here is the principle I took from it. Every architectural decision is a bet on what the business will need to do, which means you have to understand not just how the company makes money today but where it is trying to make money next. The single-tenant bet was right for B2C and wrong for B2B, and the real failure was not the original decision. It was failing to revisit that bet once the business changed, and choosing speed over the rebuild when the rebuild was the honest answer. Multi-tenant versus single-tenant, where you put the hard boundaries, what you isolate and what you share: these are not purely technical questions. They are business questions wearing technical clothes.
This is why Larson puts business mechanics first in his list of priorities for a new CTO, ahead of technical quality. The questions he opens with are “How does the business work? Where does the money come from? Where does the money go?”, and they come before any assessment of the code. It reads almost strange the first time you see it, an engineering leadership framework that opens with money instead of systems. It stopped reading strange to me the day we started the rebuild.
So the questions I would now put in week one, not month two:
- How does this company make money today, and how does that change over the next twelve months?
- What is the single technical limitation that is losing deals right now?
- What is the product team’s top priority for the next six months, and does engineering’s current state serve it or block it?
- What does the founder lose sleep over, and how much of it is actually technical?
None of those questions require reading a line of code. All of them shape every line of code you will write later.
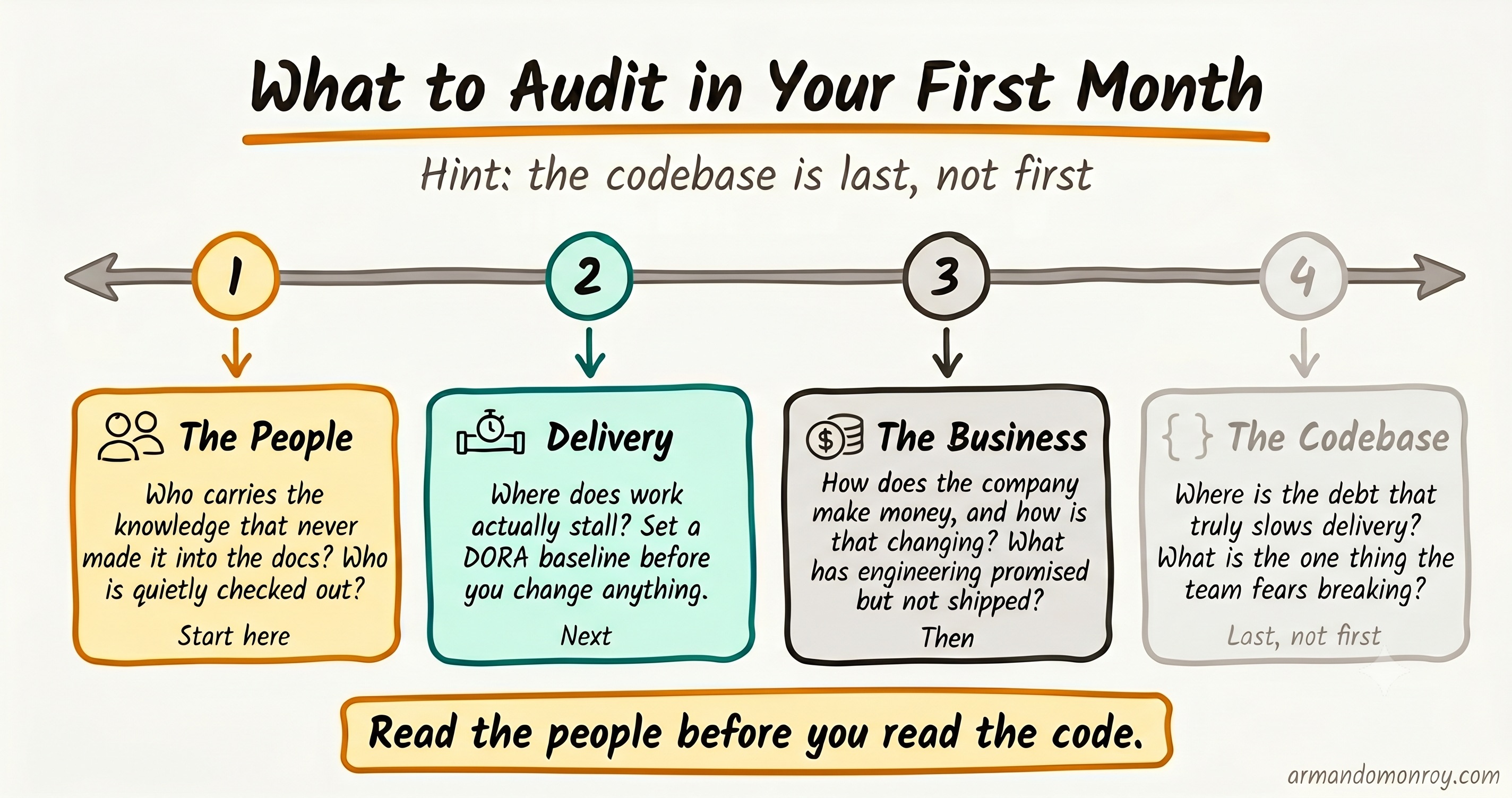
What does a month-one audit actually look like?
People hear “audit” and reach for the codebase. I would reframe the whole exercise. The things most worth auditing in your first month are mostly not in your repository, and a checklist is the wrong shape for them anyway. These are questions, not boxes to tick.
On the people: Who does the rest of the team go to when the answer is not written down? Who is quietly disengaged, and what would it take to lose them? What are the unwritten norms around code review, incident response, and ownership that nobody would think to tell you because they are too obvious to say?
On delivery: Where does the work actually stall, and is that the same place the team says it stalls? Here is where the four DORA metrics earn their place. Deployment frequency, lead time for changes, change failure rate, and time to restore service, from the research behind “Accelerate” by Nicole Forsgren, Jez Humble, and Gene Kim, give you a sound diagnostic baseline for delivery health. I want to be careful here: I am not telling you to grade your team against elite-performer benchmarks in month one. The metrics are useful because they describe where the system is, not because they hand out a score. (Setting that baseline early is also what later lets you prove a change actually worked rather than just felt like it did. I will come back to that.)
On the business: Is the sales team blocked on any deal because of a technical or compliance gap? What has the product team been asking engineering for that engineering has not delivered? What has already been promised to a customer that has not shipped? If you are at a regulated startup in healthcare or fintech, your security posture belongs on this list too, and figuring out where you stand on it early is its own first-90-days conversation.
On the codebase, last and narrow: Where is the debt that genuinely slows delivery, as opposed to the debt that merely looks bad? What is the single most dangerous point of failure? What does the team actually fear breaking? Three narrow questions, saved for the end, after the human work has told you which parts of the code matter.
From listening to deciding: the part you are actually judged on
All of that listening would be self-indulgent if it did not end somewhere. Ninety days is not a sabbatical. By the end of it, someone is going to ask what changed, and “I understand the team much better now” is not an answer a founder can take to a board. The listening is not the deliverable. It is what makes the decisions you make in the back half of those 90 days correct instead of lucky.
The arc I aim for is roughly this. The early weeks are mostly intake. Somewhere in the middle, the picture gets clear enough to start making calls. By day 90 there should be a small number of real decisions on the board, and at least early evidence that they were the right ones.
One of the first decisions came straight out of the one-on-ones. The same friction kept surfacing: code review was where work went to wait. Engineers pushed their pull requests near the end of the sprint, so reviews piled up and sat for three or four days. Stories were not ready for QA until the sprint was nearly over, QA feedback landed in the following sprint, and by then the author had moved on to a new ticket and had to swap two-week-old context back into their head to fix it. One slow review step was quietly stretching the whole feedback cycle across sprint boundaries.
We had already started bringing AI into how the team wrote code. The next place it earned its keep was review. I put AI on the first pass of every pull request, where it flagged the missing error handling, the null and edge cases, the security issues, the broken or missing tests, and the style problems, and the author fixed most of that before a human ever looked. Then I paired it with one simple expectation: thirty minutes a day on review, start of the day or end of it, your choice. That norm was easy to hold precisely because the AI had already cleared the obvious problems, so a human review was now thirty focused minutes instead of an open-ended slog. Review time dropped from three or four days to one or two, and the feedback cycle stopped spilling into the next sprint.
The setup does not require a tool. You can derive all four metrics from data you already have. A deployment, in my last company, was a release to production, so deployment frequency is how often you ship and lead time for changes is the clock from commit to that release. Change failure rate needs a definition of failure you can apply consistently. Mine was strict, taken from how the team already thought about quality: a change counted as failed if QA caught a defect before release or a bug reached production. That is tighter than the textbook version, which counts only production failures, but it matched what we actually cared about. Time to restore is the clock from a failure to its fix. Write those definitions down in week one, capture a few weeks of history as the baseline, and only then start changing things.
Not every result lands inside 90 days, and not every result needs a framework to prove it. The clearest call I made came with a hard number attached from the start. Our cloud bill was too high for the stage we were at, and most of it was structural rather than usage. So I moved us off AWS Fargate and onto Kubernetes first, which made the infrastructure portable instead of bound to one vendor’s primitives, and then moved the whole thing from AWS to Oracle Cloud. The savings were not glamorous. They came mostly from NAT gateway charges and bandwidth pricing, the kind of line items nobody notices until you add them up. Added up, they cut our infrastructure bill by 66 percent. That decision did not need a listening tour to justify after the fact, but it needed the same thing every good one does: understanding the system well enough to know which costs were structural and which were just defaults nobody had questioned.
None of this is the tool being clever or the cloud bill being an accident. The AI review worked because a specific bottleneck had been found by listening and fixed with something that fit it. The migration worked because I understood which costs were load-bearing and which were not. Drop either move onto a situation you have not understood first, and you get noise, or a migration that breaks more than it saves. The decisions were good because the context came first. That is the argument of this whole piece, made concrete.
The codebase will still be there in month two
The plan you write in your first week will be wrong in places. Mine was. That is not a failure of planning; it is the nature of arriving somewhere you do not yet fully understand. The useful question is not how to write a perfect plan. It is which parts of your plan are wrong, and you can only find that out by doing the human work first.
Larson, looking back on his own first year as a CTO, wrote that it is “better to be inevitable than fast.” At a senior level, durable improvements matter more than rapid reactions. That is not a license to produce nothing for 90 days. It means the things you do ship in that window are the right ones, made for reasons that hold up, so they last instead of unraveling the first time they are tested. The pull I felt at the start, the one I think most new CTOs feel, is toward fast: toward the codebase, because it is concrete and you can act on it today and it makes you feel like you are doing the job. The slower work, understanding the people and the business before you touch the architecture, is the work that actually compounds.
If I could go back, the change I would make is simple to say and hard to do: listen more. I was hired to make decisions, and I did make them. But I should have listened harder and longer before making them, to understand the organization well enough that my decisions improved things instead of disrupting them. The multi-tenancy rebuild was the expensive version of that lesson. The cheaper version was available the whole time, in conversations I could have had sooner.
The codebase is not going anywhere. The window to earn trust, to understand how the company makes money, and to learn the real version of how the system works is narrower than the technical problems are urgent. Spend the first 90 days on the window.
If you have done this, I would genuinely like to know: what surprised you most in your own first 90 days? The gap between the plan and the reality is where all the interesting lessons live, and most of us only learned ours the hard way.