Clinical data flows: the security architecture healthtech startups get wrong
A few months ago, I sat with a CTO who was certain his Electronic Health Record (EHR) integration was secure. The startup had implemented OAuth 2.0. The Epic sandbox tests passed. Transport Layer Security (TLS) was enabled everywhere. The team had even written down “HIPAA hardening” as a follow-on ticket for after the integration shipped. He pulled up the production access logs to show me.
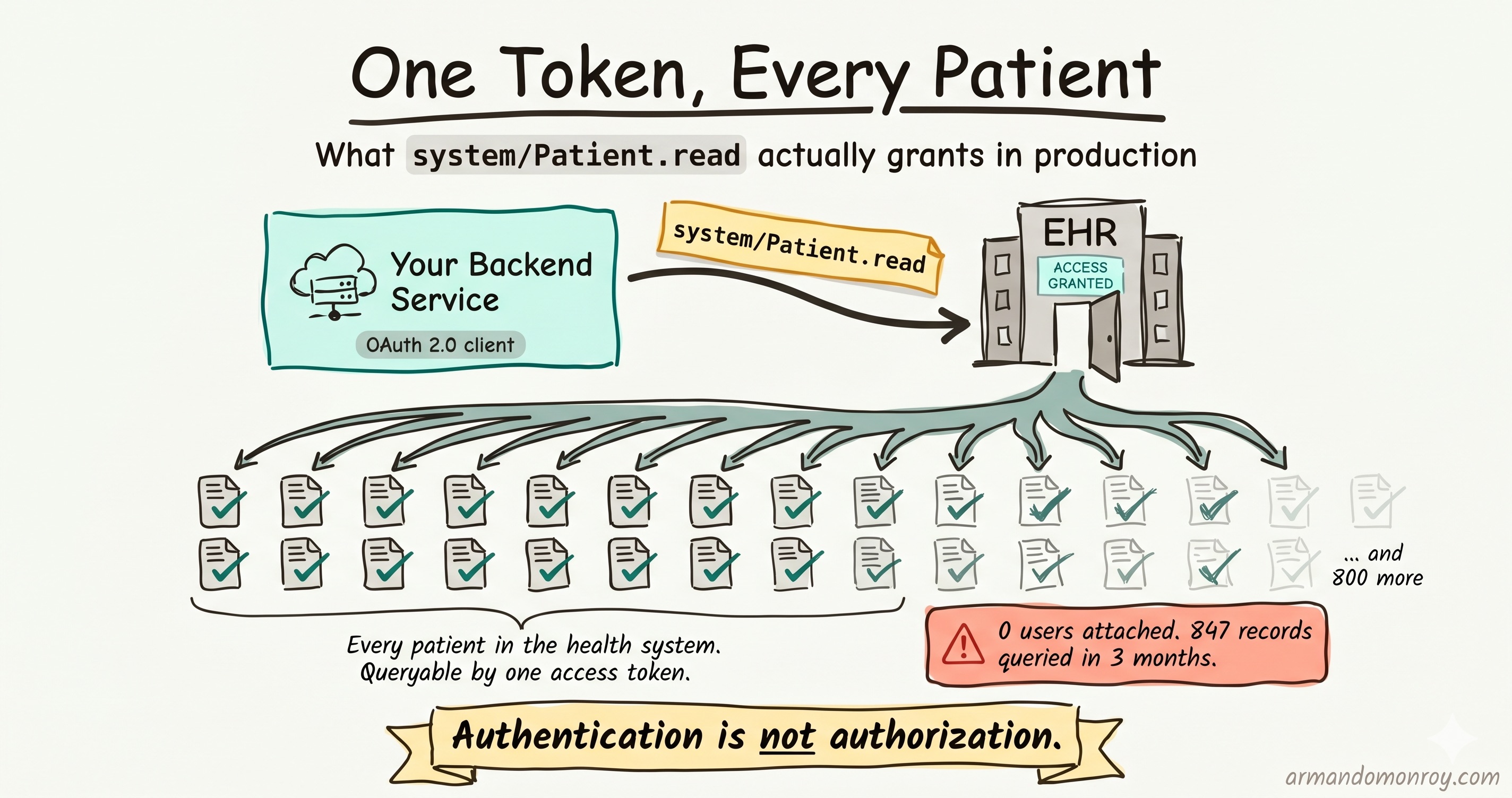
The logs showed his backend service had queried 847 distinct patient records over the past three months. There was no user attached to any of those queries. There was no way to tell which queries belonged to a clinical workflow and which did not. The service account had access to every patient in the health system’s Epic instance, and the integration had been running that way since launch.
He had not skipped HIPAA. He had implemented the authentication layer correctly and left the authorization layer at its broadest default. That is the pattern I see most often in healthtech startups, and it is the one almost nobody writes about with enough specificity to be useful.
The order of operations problem
Most healthtech startups build the EHR integration first. The product cannot demo without real clinical data. The integration is the milestone that the seed deck pointed to. Security is scoped as a follow-on task labeled “HIPAA hardening,” which is engineering-speak for “we will go back and fix this when we have to.”
By the time someone goes back, the integration architecture is frozen. Changing the scope of an Open Authorization 2.0 (OAuth 2.0) token, replacing a shared service account, or rotating a hard-coded credential requires re-registering the app with the EHR vendor, revalidating with the health system’s app review committee, and retesting in the sandbox. The structural decisions made during the first sprint are load-bearing for the rest of the integration’s life.
The premise of this post is that these decisions are not hard to get right. They are hard to change once made. The right time to make them is before the first production API call, not after a health system’s security team asks for access logs during an annual vendor review.
The most cited primary research on FHIR security is still Alissa Knight’s 2021 study, “Playing with FHIR.” Across the three production Fast Healthcare Interoperability Resources (FHIR) APIs and 48 apps tested, 100% allowed one patient’s credentials to access other patients’ records. Health Level Seven International, the organization that maintains FHIR, responded to the report and clarified that no vulnerabilities were found in the FHIR standard itself. The failures were in third-party implementations. That distinction is the editorial spine of everything that follows. FHIR is not the problem. The problem is how developers implement FHIR.
Three states of Protected Health Information, three different controls
Most engineers I talk to know the transit and at-rest split. They know to use TLS and to enable database encryption. The third state, Protected Health Information (PHI) in use, is where the gaps appear and where the assumptions break down.
PHI in transit. The HIPAA Security Rule requires encryption for transmissions of electronic PHI (ePHI) as an addressable implementation specification under 45 CFR 164.312(e)(2)(ii). In practice, this means TLS for all connections. The nuance: legacy Health Level Seven version 2 (HL7 v2) interfaces using the Minimal Lower Layer Protocol (MLLP) often do not use TLS at all, because MLLP was designed in the 1980s before network security was required. Plain MLLP over Transmission Control Protocol transmits Admit/Discharge/Transfer (ADT) notifications, lab results, and order messages in plaintext. I have walked into engagements where the team described their HL7 feed as “encrypted” because it ran over a site-to-site Virtual Private Network. That is not the same control.
PHI at rest. Encryption at rest is addressable under 45 CFR 164.312(a)(2)(iv). Under the proposed 2026 HIPAA Security Rule overhaul, encryption is moving toward a required status. I covered the broader picture of those proposed changes in my post on the 2026 HIPAA rule changes. The practical issue for startups is not the database. It is that encrypting the database is not the same as encrypting every place PHI lands. Application logs, debugging tools, message queues, object storage buckets, observability tooling, and analytics pipelines are all places PHI quietly leaks into unencrypted storage.
PHI in use. This is the state nobody writes about clearly. When the application processes a clinical record, that data is in memory, potentially written to application logs, potentially echoed in HTTP request logs, and potentially passed to a third-party service (e.g., analytics, observability, or an AI inference endpoint) that has no Business Associate Agreement (BAA) covering it. The controls here are at the code level, not the infrastructure level. Scrubbing PHI from logs before writing them. Restricting which fields are passed to third-party services. Configuring observability tooling so it does not capture request body content by default. Amazon Web Services explicitly documents that PHI can land in CloudWatch Logs if application logging defaults capture request bodies, and the AWS HIPAA workload checklist names this as a specific item to verify.
The pattern I see: a startup builds an Application Programming Interface (API) layer that calls the EHR’s FHIR endpoint, processes the returned FHIR Bundle, and passes relevant fields to its application logic. The developer adds structured JavaScript Object Notation (JSON) logging for debugging, capturing request and response objects, and sending them to CloudWatch Logs. The FHIR response includes patient demographic fields, diagnosis codes, and medication lists. All of it lands in CloudWatch in plaintext. The log group is not encrypted at rest. Every engineer with developer access to the Amazon Web Services account can query those logs. This is not a breach. But it is a discoverable HIPAA violation, because workforce members without a clinical data role have access to PHI they have no need to access.
Authentication is not authorization
FHIR R4 has reached near-universal adoption among EHR vendors, driven by the Office of the National Coordinator for Health Information Technology’s (ONC) HTI-1 Final Rule, which requires support for United States Core Data for Interoperability version 3 (USCDI v3) via FHIR APIs as of January 2025. Industry counts put roughly 92% of EHR vendors supporting FHIR R4 and 90% of health systems running FHIR-enabled APIs. The standard is everywhere. So is the implementation gap.
The FHIR R4 security specification does something specific. It states that all production data exchanges should be secured using TLS; it recommends OAuth 2.0; and it explicitly endorses the Substitutable Medical Applications, Reusable Technologies (SMART) on FHIR App Launch Implementation Guide for authorization. “Recommends” and “endorses” leave room for variation. That room is where things break.
The SMART App Launch Framework defines three scope prefixes for clinical data access:
patient/grants access to data in the context of a single patient. It requires a user login and a patient context.user/grants access to resources the authorized user can see.system/grants backend access with no user in the loop. Critically, asystem/Patient.readscope grants read access to every patient in the data store.
Here is the common mistake. During EHR sandbox testing, the system/ scopes work cleanly and do not require a patient login flow. The developer documents the working flow and ships it to production. The result is a backend service authenticated as the app, with access to every patient record in a health system’s EHR, with no patient-level authorization boundary anywhere in the integration.
This is the distinction I want to make sharp. App-level authentication authenticates the app to the EHR. Patient-level authorization decides which patients’ data the app can see. These are two separate decisions, implemented in two separate places. A lot of startups get the first right and leave the second at its broadest default because that is what made the sandbox tests pass.
The right model depends on the use case. For user-facing applications, the SMART App Launch flow issues an access token in the context of the user’s session and the user’s patient relationship. The EHR enforces patient context. The application cannot query records with which the user has no clinical relationship. For legitimate machine-to-machine work (batch lab result routing, scheduled synchronization), SMART Backend Services is the right pattern, with system/ scopes narrowed to the minimum required resource types, the service account registered separately per environment, and key rotation on a defined schedule.
The Knight research also found that 53% of mobile apps tested had hard-coded application programming interface keys and tokens. That is the same class of mistake at a different layer. The fix is the same shape: do not let convenience in the sandbox dictate what ships to production.
HL7 v2: the legacy protocol problem
Not every health system has moved to FHIR. Most large hospital networks still run HL7 v2 for ADT feeds, lab results, and order/results workflows, alongside their FHIR APIs. When a startup integrates with an interface engine like Mirth Connect, InterSystems HealthShare, or Rhapsody at a health system, they are likely receiving HL7 v2 messages over MLLP.
MLLP provides exactly two things: message framing and delivery acknowledgment. It does not provide encryption. It does not provide authentication. It does not provide authorization. The SANS GIAC paper on HL7 data interfaces walks through this fundamental flaw in some detail.
The standard remediation is MLLP over TLS, wrapping the MLLP connection in a TLS transport layer. This encrypts the message in transit and can support mutual TLS for bidirectional authentication. But many implementations skip TLS and rely on Virtual Private Network controls at the network layer instead. The pattern I see often: a startup’s engineering team says, “the connection runs over our site-to-site Virtual Private Network with the hospital network,” and treats that as equivalent to “we encrypt HL7 in transit.” It is not. The Virtual Private Network protects the network path but does not authenticate the MLLP endpoint, does not prevent lateral movement within the connected environment, and creates a single point of failure at the tunnel. HIPAA’s transmission security standard at 45 CFR 164.312(e)(1) requires controls on the transmission path itself, not just the network envelope around it.
The honest version of this conversation acknowledges that you may not control the remediation. If the health system’s interface engine does not support TLS 1.3, you will land on TLS 1.2 with cipher suites that follow NIST Special Publication 800-52 Revision 2. Requiring TLS 1.3 in a vendor questionnaire response will result in false failures for health systems with older interface infrastructure. Use “TLS 1.2 minimum, TLS 1.3 preferred.”
Data residency: HIPAA does not require what most people think it does
One of the most consistent misconceptions in healthtech procurement conversations is that HIPAA requires data residency in the United States. It does not. The HIPAA Security Rule requires appropriate controls for ePHI. It does not specify which country, cloud region, or data center those controls operate in.
The US-region requirement is set by the vendor contract, not the regulation. Health system and health plan vendor agreements often specify that PHI may be stored and processed only within the United States or specific cloud regions. This is a contractual term layered on top of HIPAA. I wrote about how these contractual terms compound in my post on BAA structuring, because data residency typically arrives as one clause among many.
The architectural consequence: if you deploy on Amazon Web Services with multi-region replication to eu-west-1 for latency or disaster recovery, and your health system customer contract specifies United States-only storage, your architecture violates the contract even though it does not violate HIPAA.
The mechanics of cloud providers are also where startups stumble. Amazon Web Services, Microsoft Azure, and Google Cloud Platform all require a signed HIPAA BAA before PHI can be processed. AWS provides this through AWS Artifact. Signing the BAA does not make every service HIPAA-eligible. PHI may only be processed on services listed in the HIPAA-eligible services inventory, which AWS currently lists at more than 160 services. Some of them, like Amazon SageMaker or AWS Glue, may require additional configuration before they actually meet HIPAA requirements in a given setup. Creating a “HIPAA account” on AWS and signing the BAA does not automatically make every service in that account audit-ready. It is the engineering team’s responsibility to verify that each new service is on the eligible list and configured correctly.
Logging that survives an audit
HIPAA’s audit control standard at 45 CFR 164.312(b) requires hardware, software, or procedural mechanisms that record and examine activity in systems that contain or use ePHI. It does not specify what must be logged, what format the logs must take, or how long they must be retained. The proposed 2026 HIPAA Security Rule overhaul would impose a 12-month minimum retention period on audit logs for ePHI access, modification, or export events, but, as of writing, this is still in rulemaking.
What an Office for Civil Rights (OCR) auditor or a health system security team actually asks for is more concrete: logs that show who accessed which records, when, from which system, and what action was taken. The practical test is whether you can produce that record for a single patient complaint. If a patient says, “I think my record was accessed without authorization on March 12,” can you show who queried the record, which application was used, and when? If your application logs say “service account A queried patient endpoint” without a user identifier, the audit trail fails.
The three layers of logging that need to be enabled, correlated, and retained:
- Application-layer audit logs. User identity, resource accessed, action taken, timestamp. This is where the FHIR AuditEvent resource belongs if you are working in a FHIR-native stack.
- Infrastructure-layer logs. API gateway access logs, container, and service logs.
- Cloud-layer logs. Amazon Web Services CloudTrail, Azure Monitor, or Google Cloud Audit Logs covering control-plane events.
This is also one of the most common categories of questions on a health system vendor security questionnaire. I covered the questionnaire workload in more detail in the security questionnaire playbook. When a health system asks “Do you maintain audit logs of all PHI access?” and “How long are logs retained?” the answers are the ones this logging architecture directly produces.
The shared service account problem
This is the architectural mistake I see most often, and the one with the longest fix timeline once it is in production.
The pattern: a startup builds the EHR integration using a single OAuth 2.0 client credential registered with the EHR vendor. All backend API calls run under this one identity. The access token is issued to the application, not to any individual user. Every patient record query appears in the EHR’s audit log as “application X accessed patient record Y.” No individual user is identified at any point in the trail.
Why it happens: it works. The EHR sandbox accepts it. Integration tests pass. The architecture is simpler because no one has to manage per-user token delegation in a backend service. Adding the right per-environment app registrations means submitting for EHR vendor review and health system go-live approval, which startups instinctively defer.
Why it fails: HIPAA’s minimum necessary standard at 45 CFR 164.502(b) requires that access to PHI be limited to the minimum necessary to accomplish the intended purpose. A shared service account with system/Patient.read has no mechanism to enforce minimum necessary. It has access to all patients regardless of whether the requesting user has any clinical relationship to them. The audit log cannot distinguish between legitimate clinical access and a curiosity query because the user is invisible to the EHR.
The mistake I described at the start of this post (the team with 847 patient record queries and no user identity attached to any of them) was the production version of this. The remediation took five months. Re-registering the app for environment separation, narrowing the system/ scopes, instrumenting application-layer audit logs with user identity, and re-running the health system’s app review process. None of those steps was difficult on its own. Sequencing them through three vendor review queues was the hard part.
I want to be precise about the nuance, because “no service accounts” is the wrong conclusion. Machine-to-machine integrations legitimately require service accounts. Batch processing, result routing, and scheduled synchronization cannot run in the context of a user session. The right model is service accounts with the narrowest workable scope, registered per environment (not shared across development, staging, and production), with documented purpose, asymmetric key authentication, key rotation on a defined cadence, and dedicated audit log tagging. A precisely scoped service account is a legitimate control. A shared wildcard service account reused across environments is the anti-pattern.
The architecture decision before the integration ships
If I had to compress this into a checklist a CTO could run through before the first production API call to an EHR, it would be these eight questions:
- Which
system/orpatient/scopes does the app request, and what is the narrowest set that still works for the actual use case? - Is the OAuth 2.0 client registered separately in development, staging, and production, with environment-specific credentials?
- For user-facing flows, does the access token carry the user’s identity and patient context, or is every query running as the app?
- For backend flows, does the application-layer audit log capture user identity even when the EHR audit log cannot?
- Where does PHI land in application logs, observability tooling, and queues that are not part of the database, and is each of those locations either covered by a BAA, encrypted at rest, or scrubbed of PHI before write?
- If you receive HL7 v2 over MLLP, is that connection running TLS at the application transport layer, not just inside a Virtual Private Network tunnel?
- Which cloud services touch PHI, and are all of them on the cloud provider’s HIPAA-eligible services list?
- If the health system asks for logs showing who accessed a specific patient record on a specific day, can you produce them, including the user identity behind the request?
If the answer to any of these is “I am not sure,” that is the work to do before the next integration ships. If the integration is already in production, that is the work to plan into the next quarter before the next vendor security review.
For startups running this work in parallel with SOC 2 (System and Organization Controls 2) and HIPAA programs, the 12-week SOC 2 and HIPAA preparation timeline covers how this fits alongside the broader compliance work, and the compliance wall post covers why this work tends to surface during procurement rather than during development.
The takeaway
The security failure I see most often in healthtech startups is failing to comply with HIPAA. It is that they implemented authentication correctly and left authorization at the coarsest possible scope, because that is what made the sandbox tests pass.
These architectural decisions are not difficult to get right when made early. They are expensive and slow to change after the integration is in production, and the EHR vendor’s app review queue is the bottleneck. The right time to think about scope, service accounts, logging, and PHI handling is before the first call from production hits the EHR, not after a health system’s annual review surfaces the gap.